スケーラブルな採番とsnowflake
snowflake は、Twitter 社が作成した、ユニークなID生成のネットワークサービスです。いくつかの簡単な保証で高いスケーラビリティを実現しています。Twitter 社が、MySQLから Cassandra に移行するにあたって、Cassandra にシーケンシャルな id 生成の仕組みが無かったことから作成したそうです。 snowflake についてはTwitter IDs, JSON and Snowflakeに書いてあります。
snowflake のコードは、Apache License, Version 2.0 でSnowflakeに公開されています。
スケーラブルな採番、背景的な話
Cloudでスケーラビリティのあるサービスを見据えてコードを書いていると採番に関する問題が必ず出てきます。従来、RDBの自動採番などに頼っていたのがコスト、スケーラビリティ、耐障害性の観点から問題となり、別の方法を考える必要が出てくるというのが一般的です。
「ID=連番」という話なら始まると話が混乱するので、基本に返って採番の要件を整理するところから初めましょう。ざっと考えたところ4つほどの条件が出てきたので、この線で話を進めます。
- ユニークである:重複が無い。これはIDをキーにしたいので当然ですね
- 時系列で増えていく(または減っていく):IDが生成される度に増加していくのは連番での重要な性質の一つです
- 秒間の発行数:採番を一箇所で行わずに分散してスケールするのがスケールする
- 連続性(連続した欠落の無い番号の生成)
最後の連続性に関しては、スケーラビリティとパフォーマンスを両立させての実現は難しいでしょう。スケールと対象外性を考えて分散環境でID生成の度にどうしてもNode間でメッセージのやりとりをせざるを得ず、パフォーマンスを犠牲にせざる得ないので、今回は外して考えます。オンプレでも限定された条件下でのみ可能な採番ですね。
これとは別に何処で採番するかという観点もあります。これは2つのパターンがあります。
- Cluster Service で採番
- クライアントで採番
Cluster Service で採番するパターンとしては、memcached/Redis などの カウンター (incr command) を使ったり、storage を使った分散counterを使ったパターンが知られています。Snowfrakeもこの1種です。クライアントでの採番は、通信を伴わないので一番速い(コストが小さい)ですが制約もあります。
採番のユニーク性
採番と考えると最低限の要求は 「一意であること UNIQUENESS」でしょう。これには、発番した時にユニーク性を担保するか、永続化したときにユニーク性を担保するかの2つの選択肢があります。採番した時に一意性を担保するパターンとしては、GUIDを使う方法よく知られています。ここでは、Guidを使う方法については深くふれません、GUIDs are globally unique, but substrings of GUIDs aren’tで面白い話が書いてあるんのでぜひ読んでみてください。(中には Snowflakeへのヒントになることも記述されています)
GUIDは非常に手軽で便利ですが、128bit(longlong)でかなり長い。時系列で並ばないなどの問題があります。
永続化レイヤーでの一意性の担保
一方永続化したときにユニーク性を担保するという考えもあります。一意なIDを振出すのはコストが高いので、擬似的な(一意性を十分期待できる)IDを振り出して永続化して可否を判断して、ダメならもう一度やってみるというのが「永続化レイヤーでの一意性の担保」の基本的な考え方です。
これは、永続化レイヤーが用意した限定された条件の下でユニーク制約を実装を利用することでユニーク性を担保するというアーキテクチャです。この場合は、「永続化レイヤーの制約」、「重複時の再試行」の2点を考慮しなければいけません。
例えば、Azure Tableでは、同一パーテーション内のRow Keyは一意であることが保証されています。他のパーテーションでは同一のRowkeyを持つことができますが、同一パーテーション内同じRawkeyは Insert できません。
この場合、Partition Key + Row Key でユニークになるので、ランダムなキーを生成して、TableにInsertできればそのパーテーション内ではユニークだと保証されるわけです。RDBのUniq制約でも同様です。Shareding されたデータベースでは、Inserできれば Shard内でユニークだという事になります。いずれも、Partition 内、 Shard 内という条件が付いていることに気を付けてください。永続化レイヤーによって異なった制約となりますが、分散システムではなんからの制約を伴うことが一般的です。
重複時の再試行
永続化レイヤーでUNIQ性を保証をする場合、「重複時の再試行」を前提としてください。クライアントがデータを永続化するまで、IDが有効かどうかわからないので、永続化した時に重複だった場合は再度IDを生成し直して処理を再試行する必要があります。
時系列で増減
IDがランダムではなく、時間と共に増加あるいは減少して欲しいことがあります。このようにIDが並んでいると、永続化レイヤーがレンジクエリーをサポートしていれば、前方一致で効率的に目的のデータを取得することができます。しかし時系列で増加するIDを発番しようとしてNodeのクロックを使うと信頼性が問題になります。
通常、複数Nodeで発番した場合は同一時刻で複数のコードが動くのでIDが重複します。それ以外にもNode内でも問題があります。Nodeのクロックは、外部のtime service に同期させているので、ローカルの時刻は随時進んだり戻ったりします。そのため、時刻だけを元に単純に採番するとIDが重複します。これらの時刻の不安定性に起因する問題を Clock Skew (クロックスキュー)問題と言います。
分散システムの問題の多くは、時刻の同期問題でもあり根が深いので、ここはスルーで先に行きます。
これらの問題を回避するために、IDの一部にランダムな要素を付与する方法が一般的に使われています。
例えば、下記のような感じ
private static void Hoge()
{
var r = new Random();
for (var i = 0; i < 100; i++)
{
var id = string.Format("{0:D19}_{1:D4}", DateTime.Now.Ticks, r.Next(10000));
Console.WriteLine(id);
}
}
ここで発番しているのは擬似的なUNIQ性を持ったIDでです。最終的なUNIQ性の保証は別のレイヤーに預ける前提です。ランダム桁数は、衝突の頻度と衝突時の再試行のコストを鑑みて決定します。この例だと、4桁取っていますが、昨今のCPUだとシングルCoreで同一Tick内で2-3程度は発番できるようなので、100coreぐらいあれば、2*100/10000 = 1/50 となって、結構な頻度で衝突します。(この数字は結構いい加減なので参考程度で)
順番を逆にしたい場合は、下記のようにします。
private static void Hoge()
{
var r = new Random();
for (var i = 0; i < 100; i++)
{
var id = string.Format("{0:D19}_{1:D3}", long.MaxValue - DateTime.Now.Ticks, r.Next(1000));
Console.WriteLine(id);
}
}
こうすると、最新のものが最初にきます。先頭から指定行を取得するようなクエリーをサポートしている永続化レイヤーで最新の情報を取得する場合にはこの並びが便利に使えます。
秒間の発行数
秒間どれぐらいの数のIDを生成可能なのかも重要なファクターです。一般的にオンメモリで計算のみで発番するものが一番速く、永続化付きKVS、RDBMSの順の速度になります。
ID生成はクラスターで行って、分散することでスケールするというのは基本的な考え方で、その場合ID生成クラスターのNodeコストが問題となります。一般的にメモリーで計算のみで発番するものはIDのユニーク性と耐障害性の両立が難しく、なんからの永続化をすることで問題を回避するという方法が取られる場合が多いようです。RDBはID生成を目的としてクラスター化するにはコスト高いのが問題となると思います。
クライアントで擬似的なUNIQ IDを生成して、永続化時に担保させるという方法はリーズナブルにスケールする方法だと言えます。
Snowflake
Clock Skew に上手く対応することで、オンメモリの計算と最低限のノード間通信でUNIQなIDを生成する仕組みです。永続化レイヤーの支援無しにUNIQなIDが生成できる、オンメモリなので速い(10k ids per second per processSnowflake)というのが特徴です。
ある意味GUIDと似ているのですが、64bit(long) で実現しているところ、おおよそ時系列で増えていく「(Roughly) Time Ordered」なことが異なっています。
データ構造
snowfake では、64bitを下記のように分割して使います。timeが時間由来の数字でミリ秒単位です。machine id は、datacenter id と、worker idで構成されていて、Cluster内のNode固有の値になります。sequence number は、同一時間(timeが同じ)間にカウントアップされていく連番です。
| 64 bits | ||||
|---|---|---|---|---|
| 0 |
|
machine id 10bit |
|
|
| datacenter id 5bit | worker id 5bit | |||
前記の時間ベースのID生成と比較すると、IDにNode固有の番号(machine id)が含まれている、同一時間内の採番では乱数ではなくカウンターを使って重複を避けていることが異なっているのがわかります。
実は、この構成は GUID V1と似ています。GUID V1 は、 timestamp 60 bits、computer identifier (MAC Address) 48 bits、uniquifier (乱数+シーケンス)14 bits、fixed ()バージョン等) 6 bits から構成されています。全体的にGUIDの方がBitの使い方がリッチで余裕がある構成です。データは、DWORD-WORD-WORD-WORD-BYTE[8] として扱われます。Endian の問題もあってtimestamp由来なのに時系列で並びません。timestampは、100 ns 単位です。
snowflake は、GUIDを64 bits (正確には最上位が0固定のなので63 bits)に押し込んでUNIQ性を確保しています。
ではどうやって64bitに押し込んでいるのでしょう。
- 範囲の制限: 簡単に言うと、GUIDは グローバルにUNIQだけど、snowflakeは発番体系内でUNIQです。別のサービスで使っている snowflake clusterと比較するとUNIQ性は保証されません。ここは大きな違いですが、別サービスとIDが被るのは問題無いので、実用上は制限にはなりません。これで、MAC Address 48 bits の所を10 bits に押し込めています。
- timestampの精度と範囲: GUIDは、100 ns 、snowflakeは、1 ms です。timestamp の精度を下げ、開始時間(0の時の日時、何時からの時間なのか)をサービス開始時などに合わせることで、timerのラップアラウンドの問題を軽減しています。(2^41)*(10^-3)/60/60/24/365 で約69年持ちます。ちなみにGUIDは、(2^60)*(10^-7)/60/60/24/365 で3655年以上持ちます。開始は、1582/10/15 0:00 です(3千年以上もつの開始はあまり重要じゃないですね)69年保てば問題無い気がしますね。これで、41 bitsにしています
ソースコード上での工夫
なかなか興味深かったので、IdWorker.scalaをC#で写経してみました。(scala が非常に分かりやすくて感動しました)
基本的な流れは、非常にシンブルです。
NextId()をざっと見てみましょう。
- 現在のtimestamp を取得L60
- 最後に発番してからtimestampが戻っていないか確認L63
- 巻き戻っていればエラーで帰る(呼び出し側が再試行する)L66
- 同一timestampなら、_sequence をインクリメントして採番L72
- timestamp が進んでいれば、_sequence = 0で採番L82
この他は、下記のコードがポイントです。
timestampの開始時間を、採番開始時間にオフセットさせるL87
同一 timestamp 内で、_sequence がオーバーフローした場合は、timestampが変わるまで待つL75
この他に、Worker Idの管理には、zookeeper を使っているなど興味深いところはありますが、今回はこの辺でまとめます。
最後に
実は、この記事を書いている途中に、Global Microsoft Azure Bootcamp 2014があり、このネタで発表してしまったので長らくお蔵入りしていました。読み直してみたら、セッションでは時間の都合で話をしなかった内容もあり、それなりに役に立つかなと思ったので公開します。肝心のsnowflake の採番が速い理由が書いてありませんが、採番node間の通信が最低限で(生きているかどうか)、重複採番の防止にしか使われていないのが、一番効いている気がします。
合わせて、セッション資料も御覧ください。
FiddlerCoreでRead-Access Geo Redundant Storage を検証する
Windows Azure – 技術者でつなぐ日めくりカレンダーの 3/2 の記事です。先日、Windows Azure 4周年記念 & Japan DCオープンマジデシタ!JAZUG大会のLTで、Azure Storageには3つの可用性設定があるという話をしました。例によって、時間内には収まらず。「続きはWebで・・・」ということで続きです orz
まずはLTの内容の復習から、簡単にまとめると下記のような内容です。
振り返り
Azure Storageの可用性設定(冗長構成)には3種類ある。
- ローカル冗長ストレージ (LRS=Locally Redundant Storage)データセンター内3箇所、同期
- 地理冗長ストレージ (GRS=Geo Redundant Storage)地理的に離れた場所への複製(Local 3箇所+リモート3箇所)、リモートは非同期、フェイルオーバー
- 読み取りアクセス地理冗長ストレージ (RA-GRS=Read Access - Geo Redundant Storage) PREVIEW地理的に離れた場所にあるデータを読む機能
読み取りアクセス地理冗長ストレージ (以下、RA-GRS)は、現状Previewなので、まずはWindows Azure Previewのページで申し込みをする必要がある。
SDKの対応状況
RA-GRSの新機能を使うには REST version 2013-08-15 を使うStorage SDKが必要。ただし、RESTでEndpointが違うだけだから自前でもアクセスするだけならそんなに難しくない。
- .NETだと、Storage Client Library 3.0以降
- Javaだと、Windows Azure Storage SDK for Java 0.5.0以降
- その他、各自対応
上記2つのSDKには、Blobs, Tables and Queues の最終同期時刻(Last Sync Time)をクエリーする機能と primary にアクセしできなかった時に secondary に自動的に retry する機能、並びにLocationMode で参照先の設定がる。リトライは、IRetryPolicyを拡張した IExtendedRetryPolicy が追加されている。これではリトライ時に参照先を切り替えするようになっている。
LTの資料
RA-GRS Windows Azure Storage LT
ここからが本題です。
確認する
RA-GRSで障害が起きた時のIExtendedRetryPolicyの動作確認をしたいのですが、そうは都合良くデータセンターの障害が起きるわけはありません。デバッガーでBreakしてネットワークを切断するとか、変数を書き換えるとかの方法もありますが、なんども繰り返すのは手間が掛かるしパターン増やすと面倒です。そんな時に、丁度いいタイミングでCLR/H in Tokyo 第1回で過酷な争奪戦に勝利し「実践Fiddler」をゲットしました。

FidderCoreを使うとHTTP通信の途中に割り込んで内容を変更することが簡単に出来ます。フルスクラッチでProxy書いて「ゴニョゴニョ」すると結構手間がかかるので、今回は、FeddlerCoreを使って サクッとLocationMode.PrimaryThenSecondary を指定した時のリトライ動作を確認します。本にはいろいろ詳しく書いてあるので、興味が出た方は是非!
準備
下記の場所から、インストーラーを落としてきて入れます。exeが落ちてくるのでインストールすると、FiddlerCoreAPIというディレクトリーに入ります。
http://www.telerik.com/fiddler/fiddlercore
インストール先のFiddlerCoreAPI\DotNet4\FiddlerCore4.dllを参照に追加します。
今回読み込みアクセスを試したいので、予めBlob にファイルを上げて起きます。
Blobからのダウンロードのコードは下記のような感じです。CloudBlobClient の LocationModeを設定しています。Client全体の設定はここで書き、ここのリクエストでは、BlobRequestOptionsで設定します。それ以外は普通のBlobからDownloadするコードですね。try の次の行ので読んでいる、FiddlerCoreSetup()でFiddlerCoreの設定を行っています。
static void Main(string[] args)
{
var connectionString = CloudConfigurationManager.GetSetting("ConnectionString") ?? "UseDevelopmentStorage=true";
var account = CloudStorageAccount.Parse(connectionString);
var client = account.CreateCloudBlobClient();
try
{
FiddlerCoreSetup(client.StorageUri.PrimaryUri.Host);
// プライマリ→セカンダリで切り替え
client.LocationMode = LocationMode.PrimaryThenSecondary;
var container = client.GetContainerReference("jejeje");
var blob = container.GetBlockBlobReference("cray.png");
blob.DownloadToFile("cray.png", FileMode.OpenOrCreate);
}
finally
{
FiddlerCoreShutdown();
}
}
FiddlerCoreSetup() の中を見てみましょう。基本的には必要な処理をFiddlerのイベントハンドラに追加して、FidderCore プロキシを起動するだけです。
private static void FiddlerCoreSetup(string blockedHostName)
{
FiddlerApplication.AfterSessionComplete += os =>
Console.WriteLine("AfterSessionComplete Session {0}({4}):{1} {2} {3}",
os.id, os.responseCode, os.RequestMethod, os.fullUrl, os.oResponse.MIMEType);
FiddlerApplication.BeforeRequest += os =>
{
if (os.HostnameIs(blockedHostName))
{
Console.WriteLine("BeforeRequest Session {0} {1} {2}", os.id, os.hostname, os.host);
os.host = blockedHostName + ".jejeje";
}
};
FiddlerApplication.Startup(0, FiddlerCoreStartupFlags.ChainToUpstreamGateway);
var endpoint = string.Format("127.0.0.1:{0}", FiddlerApplication.oProxy.ListenPort);
var feddlerProxy = new WebProxy(endpoint);
WebRequest.DefaultWebProxy = feddlerProxy;
Console.WriteLine(endpoint);
}
private static void FiddlerCoreShutdown()
{
FiddlerApplication.Shutdown();
}
ちょっと細かく追いかけてみます。
AfterSessionCompleteはHTTP セッションが完了した後に生成されるイベントです。 このイベントハンドラにロギング代わりにコンソールへの書き出しを追加します。。今回は、ここのログを見て何処にアクセスに行っているのかを確認します。
BeforeRequestはHttp リクエストのデータが揃いサーバーに接続する前に生成されるイベントです。このイベントハンドラに、Primary のホストが接続先だったときに、存在しないhostに繋ぎに行くようなハンドラを追加します。
FiddlerApplication.Startup()を呼び出して、FeddlerCoreプロキシインスタンスを起動します。ポートに0を指定すると、FeddlerCore が自動的に空いているポートを探してリスニングに入ってくれます。ポートが使用中の問題が発生しないので便利なので、ポート番号を固定したいとき以外は0で良いと思います。自動で割り当てられたポート番号は FiddlerApplication.oProxy.ListenPort で確認できます。
今回は、このアプリケーションから出るリクエストだけ操作できればいいので、FiddlerCoreStartupFlagsにChainToUpstreamGatewayを指定します。その他に、システム全体のProxyに入りたい場合は、RegisterAsSystemProxyを使います。
そして、WebRequestのDefaultWebProxyを、FeddlerCoreプロキシ で書き換えます。これで、Azure Storage Client のリクエストが、Primary に向いているときは失敗するようになりました。
これで、実行すると下記のようになります。
127.0.0.1:19282
BeforeRequest Session 1 ragrsomi001jp.blob.core.windows.net ragrsomi001jp.blob.core.windows.net
AfterSessionComplete Session 1(text/html):502 GET http://ragrsomi001jp.blob.core.windows.net.jejeje/jejeje/cray.png?timeout=90
AfterSessionComplete Session 2(image/png):200 GET http://ragrsomi001jp-secondary.blob.core.windows.net/jejeje/cray.png?timeout=90
最初に、Primary にアクセスし、その後 Secondary にアクセスし直しているのがわかります。
Primary へのアクセスが502 Bad Gatewayなのはちょっとイマイチですが、FeddlerCoreがProxyで入るので仕方がないのかもしれません。
まとめ
実は、FeddlerCoreは、Azure Storage ClientのUnit Testでも使われています。GitHub azure-storage-net HttpMangler.cs今回は非常に簡単な例を紹介しましたが、FeddlerCoreを使うとレスポンスを偽装したり変更したりなど柔軟にできて、通常エラーにならないような場合のテストケースを作ることができます。手軽に使えるのでカジュアルに使っても便利ですし、がっちりUnitTestを作るときにも役に立ちます。
CLR/H in Tokyo 第1回はいろいろ知らないことを聴けたので面白かったですね。特に、技術者のブランディング戦略の重要性と独自の進化を遂げたプロビジョニング、構成管理ツールの話が秀逸だった。
最後に1つだけ、FiddlerCore をnugetで配布してくれると嬉しいなぁ・・・
Windows Azure Storage Emulator 2.2.1 Preview
Azure Storage 愛好者待望の、Azure Storage Emulator の 2013-08-15 version サポートがリリースされました。(まだ、preview ですが)
Windows Azure Storage Emulator 2.2.1 Preview Release with support for “2013-08-15” version
Windows Azure Storage Emulator 2.2.1 Preview Release の MSI package は、ここからダンロードできます。

インストールの手順
この release では、Windows Azure SDK 2.2 が予めインストールされている必要があります。これは preview release で、インストーラーは、Windows Azure Storage Emulator 2.2 のバイナリーを自動では入れ替えません。代わりに、32bit OSでは、"%ProgramFiles%\Windows Azure Storage Emulator 2.2.1\devstore"に、64 bit OSでは"%ProgramFiles(x86)%\Windows Azure Storage Emulator 2.2.1\devstore"にバイナリーを展開します。
更新されたエミュレータ(2.2.1 preview)を利用する場合は下記のステップを踏んでください。
- Storage Emuratorの停止
- "%ProgramFiles%\Microsoft SDKs\Windows Azure\Emulator\devstore"にある既存のファイル(2.2)を他のディレクトリに保存
- 新たにインストールされた2.2.1 preview のファイルを"%ProgramFiles%\Microsoft SDKs\Windows Azure\Emulator\devstore"へ上書き
以前のエミュレータ(2.2)に戻す場合は、Storage Emuratorを停止して保存したファイルを戻します。この方法で、簡単に2.2のStorage Emuratorに戻すことができ、SDK 2.2の再インストールなどは必要ありません。
これはちょっと手間ですが、Windows Azure Storage Emulator 2.2.1 Preview Release with support for “2013-08-15” versionによると、preview のための暫定的な処理のようです。
Do It
やってみます。まず、最初にAzure Storage Emulatorが動いていたら止めます。
Windows Azure Storage Emulator 2.2.1 Preview Release の MSI package を、ここからダンロードしてきてインストールします。

インストールが終わると、README.txt が表示されます。上に書いたようなことが書いてあります。
手元はx64環境なので、"%ProgramFiles(x86)%\Windows Azure Storage Emulator 2.2.1\devstore"にファイルが有るかを確認します。インストーラーは、ここにファイルを展開しますが、ここだと実行されません。これから規定の場所にコピーします。
問題無さそうなので、"%ProgramFiles%\Microsoft SDKs\Windows Azure\Emulator\devstore"のファイルをZIPで固めて避難してから、2.2.1のファイルをコピー上書きします。
確認
まずはStorage Emulatorを実行して起動を確認します
普通に Windows Azure Storage Emulator - v2.2 のショートカットをクリックする方法以外に、下記のようにコマンドラインから起動をすることも出来ます。
$ .\csrun.exe /devstore
Windows(R) Azure(TM) Desktop Execution Tool version 2.2.0.0
for Microsoft(R) .NET Framework 4.0
Copyright c Microsoft Corporation. All rights reserved.
Starting the storage emulator...
$
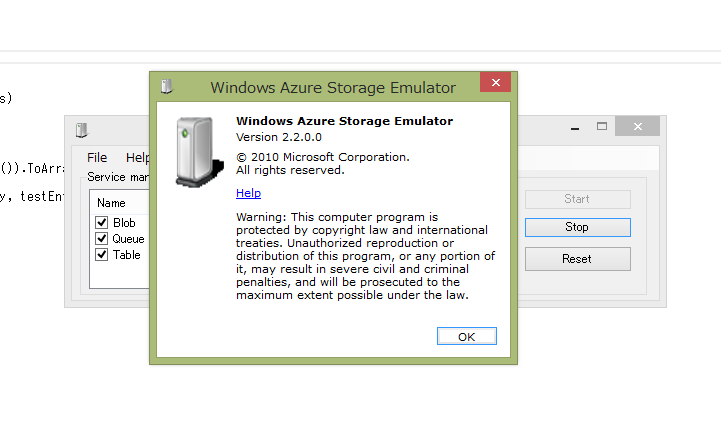
起動してきたので、念のためバージョン番号を確認します。残念ながら変わっていません…
次にJSONでアクセスしてみます。Install-Package WindowsAzure.Storage後、下記のようなコードを書いて実行します。
using System;
using System.Linq;
using Microsoft.WindowsAzure.Storage;
using Microsoft.WindowsAzure.Storage.Table;
namespace WASE221pre
{
public static class Program
{
public static void Main(string[] args)
{
var acct = CloudStorageAccount.DevelopmentStorageAccount;
var tableClient = acct.CreateCloudTableClient();
var table = tableClient.GetTableReference("TestTable");
table.CreateIfNotExists();
var entity = new TableEntity
{
PartitionKey = "pk",
RowKey = string.Format("rk{0}", DateTime.UtcNow.Ticks)
};
table.Execute(TableOperation.Insert(entity));
var rows = table.ExecuteQuery(new TableQuery<TableEntity>()).ToArray();
foreach (var testEntity in rows)
Console.WriteLine("{0}, {1}", testEntity.PartitionKey, testEntity.RowKey);
}
}
}
<?xml version="1.0" encoding="utf-8"?>
<packages>
<package id="Microsoft.Data.Edm" version="5.6.0" targetFramework="net451" />
<package id="Microsoft.Data.OData" version="5.6.0" targetFramework="net451" />
<package id="Microsoft.Data.Services.Client" version="5.6.0" targetFramework="net451" />
<package id="Microsoft.WindowsAzure.ConfigurationManager" version="1.8.0.0" targetFramework="net451" />
<package id="Newtonsoft.Json" version="5.0.8" targetFramework="net451" />
<package id="System.Spatial" version="5.6.0" targetFramework="net451" />
<package id="WindowsAzure.Storage" version="3.0.2.0" targetFramework="net451" />
</packages>
実行結果
$ WASE221pre.exe
pk, rk635265773262439816
pk, rk635265773303542415
pk, rk635265773965590960
pk, rk635265774455960355
pk, rk635265824937388844
上手く行きました。(何度か実行したので複数のエンティティがあります)
本当にJSONで流れているのかどうか念のために確認します。
接続文字列を、"UseDevelopmentStorage=true;DevelopmentStorageProxyUri=http://ipv4.fiddler"に変更します。
// var acct = CloudStorageAccount.DevelopmentStorageAccount;
var acct = CloudStorageAccount.Parse("UseDevelopmentStorage=true;DevelopmentStorageProxyUri=http://ipv4.fiddler");
実行してCaptureを確認します。
リクエスト
GET http://127.0.0.1:10002/devstoreaccount1/TestTable?timeout=90 HTTP/1.1
User-Agent: WA-Storage/3.0.2 (.NET CLR 4.0.30319.34003; Win32NT 6.3.9600.0)
x-ms-version: 2013-08-15
Accept-Charset: UTF-8
MaxDataServiceVersion: 3.0;NetFx
Accept: application/json;odata=minimalmetadata
x-ms-client-request-id: a4ed326b-e3a6-43f9-bb6e-8fb295014473
x-ms-date: Wed, 29 Jan 2014 09:04:42 GMT
Authorization: SharedKey devstoreaccount1:7Wt86EphqhTZTwLxkMrAkPGNV9WDSKa0df5Feaw8zkU=
Host: 127.0.0.1:10002
レスポンス
HTTP/1.1 200 OK
Cache-Control: no-cache
Transfer-Encoding: chunked
Content-Type: application/json;odata=minimalmetadata;streaming=true;charset=utf-8
Server: Windows-Azure-Table/1.0 Microsoft-HTTPAPI/2.0
x-ms-request-id: fdd3f33e-e2d7-401e-a4c6-7654bd7ae584
x-ms-version: 2013-08-15
X-Content-Type-Options: nosniff
Date: Wed, 29 Jan 2014 09:04:42 GMT
285
{"odata.metadata":"http://127.0.0.1:10002/devstoreaccount1/$metadata#TestTable","value":[{"PartitionKey":"pk","RowKey":"rk635265773262439816","Timestamp":"2014-01-29T07:28:46.35Z"},{"PartitionKey":"pk","RowKey":"rk635265773303542415","Timestamp":"2014-01-29T07:28:50.513Z"},{"PartitionKey":"pk","RowKey":"rk635265773965590960","Timestamp":"2014-01-29T07:29:56.707Z"},{"PartitionKey":"pk","RowKey":"rk635265774455960355","Timestamp":"2014-01-29T07:30:45.74Z"},{"PartitionKey":"pk","RowKey":"rk635265824937388844","Timestamp":"2014-01-29T08:54:54.147Z"},{"PartitionKey":"pk","RowKey":"rk635265830822644693","Timestamp":"2014-01-29T09:04:42.46Z"}]}
0
無事に動いていることを確認できました。
最後に
preview ですが、Storage Emulatorが 2013-08-15 versionをサポートし、軽くですがJSONでのアクセスが動くことを確認できました。12月のWindows Azure Storage Client Library for C++ Previewでは、2013-08-15 version 対応のStorage Emulator が、来月には出せそうということだったので、ほぼ予定通りですね。どうしても手元で確認したい場合は、Storage Emulator 2.2.1 previewを使って、そうでない場合は本番を利用して開発ということになりそうです。
Windows Azure Storage 3.0.2 Hotfix
2014/1/4Windows Azure Storage 3.0.2がリリースされました。2013/11/27 3.0のリリース 「Windows Azure Storage Release - CORS、JSON、Minute Metrics の紹介」、2013/12/11 の 3.0.1 hotfix 「Windows Azure Storage Client 3.0.1」 に続く3回めのリリースです。

修正点
- All (WP): 多くのAPIで ArgumentOutOfRangeException になる問題の修正
- Queues: 存在するqueueの再度作成で、NullReferenceException になる問題を修正
- Tables: レスポンスがparseできなかったときに、TableServiceContext が NullReferenceException になる問題を修正
- Tables (RT): JSON形式がまだRT library でサポートされていないため、ユーザーは、RTで RequestOptions に JsonFullMetadata formart を設定することはできません
コードを確認したところ、最初のやつが興味深いものでした。
1. All (WP): 多くのAPIで ArgumentOutOfRangeException になる問題の修正
対象は、Windows Phone プラットフォームだけで特定のAPIでなく全般的に発生します。関連する Issue として 、System.ArgumentOutOfRangeException in Microsoft.WindowsAzure.Storage.Table.CloudTable.EndExecuteが出ています。
共通で使っている、API内のパラメータのバウンダリー検査関数(AssertInBounds)が動いていなくてあちこちで問題が発生するということになっていたようです。(そうは言っても、テストはしているので、そうそう起きるわけでは無いとは思います)
Storage Client Library 3.0.2 のPRでdiffを見みると、WINDOWS_PHONEだけで下記のように修正されていました。
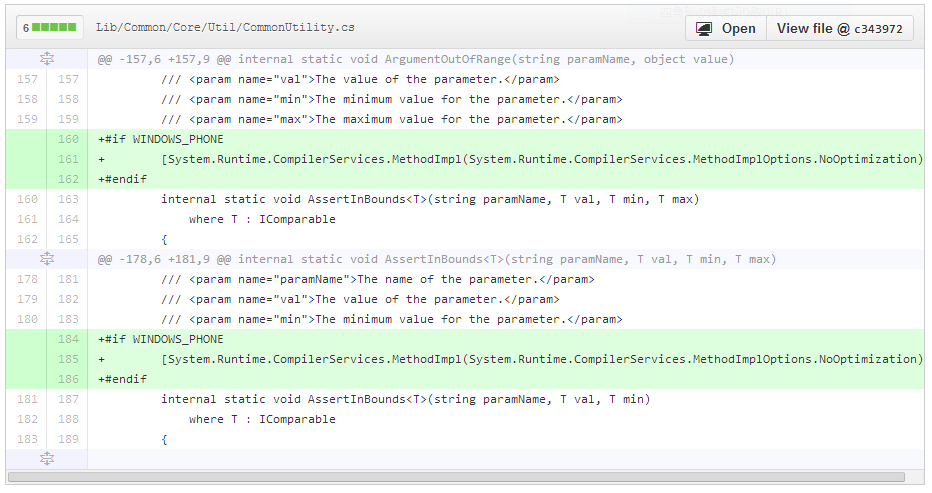
#if WINDOWS_PHONE で AssertInBounds に、[System.Runtime.CompilerServices.MethodImpl(System.Runtime.CompilerServices.MethodImplOptions.NoOptimization)]を指定しています。この指定は、JITやNGENでのコード最適化を抑制するもので、[1]Windows Phone の場合だけ native code 生成に問題があったので抑制するオプションを付けたということです。
Windows Phone というだけで、どのような場合に発生する問題かなどわかりませんが、WP アプリのコードが挙動不審の場合は試してみると良いかもしれません。Storage Clinet Library内では、この方法で修正されているようなので問題は無いのですが、普通に書いたコードでも起きるとすると、ちょっと困りますね。もう少し詳しい情報が欲しいところです。[2]
これ以外は、あまり気になる点はありませんでした。互換性の問題も無さそうなので、3系のStorage Clinetは 3.0.2 を使うのがお勧めです。
2014/1/11 追記 Windows Phoneの問題
PR の質問に返事を貰いました。
この問題は、Windows Phone でだけ起き、assemblyに、AssertInBoundsとAssertInBounds 両方が存在する場合に、最適化で実行時にAssertInBoundsの間違ったインスタンス化を選択することによって引き起こされる
internal static void AssertInBounds<T>(string paramName, T val, T min, T max) where T : IComparableと、internal static void AssertInBounds<T>(string paramName, T val, T min) where T : IComparableの両方が同一 assembly にあるのが問題のようです。 必ず起きるというわけでも無さそうなので、Windows Phone で嵌ったら思い出してみるという程度で良さそうです。
| [1] | About System.Runtime.CompilerServices.MethodImplOptions |
| [2] | We escalated this internally … |