2017 Microsoft MVP Award を受賞しました
2017年7月期、Microsoft Azure のカテゴリで、Microsoft MVP Award を受賞しました。
今年は、Cosmos DBの年ですね、楽しみな年になりそうです。
これからも、よろしくお願いいたします。

Azure に OAuth 2.0 Device Flow でログインする
この前az loginでログイン出来なくなった時に、azure cli 2.0 のコードを見ていたら、Azureのドキュメントには出てこない(見慣れない)使い方をしてたので確認も兼ねて生REST、OAuth 2.0 Device Flow[1]でAzrueにloginして Beare Tokenを取得するコンソールプログラムazlogin[2]を書いてみた。

使い方
azloginを実行すると、azure cli 2.0 と同じように、デバイスコードと入力用のURLが表示される。この画面のメッセージがazure cli 2.0と一文一句違わず同じなのは、AIPが返して来るメッセージをそのまま表示してるからだ。
ログインに成功すると、アカウントに紐づいたテナントを全部取得して、テナントのアクセストークンを取得し、それを使ってサブスクリプションの情報を取得。結果をJSONで出力する。
$ .\azlogin
To sign in, use a web browser to open the page https://aka.ms/devicelogin and enter the code G9HFZ4NCY to authenticate.
....
[
{
"tenantId": "xxxxxxxx-xxxx-xxxxxxxxx-xxxxxxxxxxxx",
"subscriptionId": "xxxxxxxx-xxxx-xxxxxxxxx-xxxxxxxxxxxx",
"subscriptionName": "Developer Program Benefit",
"bearer": "********************************************a"
},
{
"tenantId": "xxxxxxxx-xxxx-xxxxxxxxx-xxxxxxxxxxxx",
"subscriptionId": "xxxxxxxx-xxxx-xxxxxxxxx-xxxxxxxxxxxx",
"subscriptionName": "foo",
"bearer": "********************************************a"
},
{
"tenantId": "xxxxxxxx-xxxx-xxxxxxxxx-xxxxxxxxxxxx",
"subscriptionId": "xxxxxxxx-xxxx-xxxxxxxxx-xxxxxxxxxxxx",
"subscriptionName": "kinmugi",
"bearer": "********************************************a"
}
]
このJSONから、Bearer token を取得し変数に保存するして置き、APIの呼び出しをしてみよう。
まずは、jp (JMESPath) の式を用意する。短いのでコマンドラインにそのまま書きたいところだが、Windowsだとエスケープ関係が難しすぎる(cmd.exeや、powershellでは)ので、諦めてファイルに書く。
この例だと、subscriptionName が ‘kinmugi’のサブスクリプションのBearer tokenを取り出している。Windowsだと素直にPowerShellで書いたほうが楽な気がする。最近、JMESPath が気に入っているので、あえてjpを使う。
ここでは、本物のcurlを使って、リソースグループの一覧を取得している。PowerShellだとcurlでaliasが切ってあるが使えないので、本物を入れてalias を切った方が良い。
$ cat filter.jp
[?subscriptionName == 'kinmugi'].bearer|[0]
$ $bearer = (.\azlogin | jp -u -e filter.jp)
$ curl -H "Authorization: Bearer $bearer" "https://management.azure.com/subscriptions/xxxxxxxx-.../resourcegroups?api-version=2017-05-10"
Bearer tokenさえ手に入れれば、こんな感じでサクッと管理APIが呼べる。
最後に
Azureのドキュメントだとごちゃごちゃしてて良くわからないが、認証は基本普通のOAuth 2.0 なのでそれほど難しくない。このあたりで困ったら、OAuth2.0 のドキュメント(Googleのとか 、翻訳もある[3])を読むと良い。Azure固有の問題は、松崎さんのブログ[4]がお勧めだ。
今回は、生RESTだけで構築したが、認証だけならそれほど難しいことはない。本格的にAzureを触ろうと思うとモデルが欲しくなり。触っていくと大量のモデルが出てくるので自前で作るのはとてもメンドクサイ。その場合はAzureSDKを使うと既にモデルが用意去れているので便利だ。
参考
| [1] | Using OAuth 2.0 to Access Google APIs,OAuth 2.0 for TV and Limited-Input Device Applications, |
| [2] | Azure Login OAuth 2.0 Device Flow Console Program. |
| [3] | OAuth 2.0 Flow: DevicesYouTube Data APIのドキュメントだが、翻訳されている。 |
| [4] | Login UI が出せない Client の OAuth フロー (Azure AD)この記事より松崎さんのブログを読んだほうが良いだろう。 |
下記のコードも参考になる
Azure PowerShellのインストール事情
最近のAzure PowerShellのインストール事情が少々メンドクサイことになっているのでメモ代わりに書き留める。
基本は、Azure テクニカル サポート チームがAzure PowerShell 最新版のインストール手順 (v3.8.0 現在)に書いている状況だが、いろいろあるので書いた。
更新: 2017/7/7、Azure PowerShell 4.1.0 時点の情報
この問題を、VSのフィードバックに上げた所返事が来ました。
https://developercommunity.visualstudio.com/solutions/67232/view.html
To work around the issue please install the latest Azure PowerShell MSI from GitHub.
「VS 2017を入れている場合は、とりあえず MSI経由のインストールをして欲しい、最新版は、GitHubのリリースページにあるよ」ということで、色々あるけど当面はMSIで入れましょう。
2017/5/19、Azure PowerShell 4.0.1 時点の情報です

推薦されるインストール方法
以前は、WebPI経由でAzure PowerShellをインストールしていたが、現在では PowerShell Gallery 経由のインストールが推薦になっている。公式ドキュメント、Install and configure Azure PowerShellにも、下記のように書かれている。(ちょっと翻訳が追いついていないようで、サイトは英語のまま)
Installing Azure PowerShell from the PowerShell Gallery is the preferred method of installation.
Windows 10、Windows Server 2016より古いOSではデフォルトでPowerShellGetが使えないので、Windows Management Framework (WMF) 5.0 を入れる必要がある[1]。
PowerShellGetでPowerShell Galleryから方法は簡単だ。(以下、Install-Moduleで入れると記載)
$ Install-Module AzureRm
MSIからのインストール
Install-Moduleで入れる方法の他に。Web Platform Installer (WebPI) やVisual Studio 2017のVisual Studio Installer での、Azure「Azure development」の選択、GitHubからMSIファイルをダウンロード[2]などの方法で、MSIファイルからインストールすることができる。MSIファイルからインストールは推薦されていないが、VS経由の時にように選択の余地なくMSI経路でインストールされてしまうこともある。
また、ググって出てくる日本語の公式ページがその他のインストール方法で、その他の方法としてMSIでのインストール方法を紹介している。ここには推薦は、Install-Moduleを使うことだと書いてあるが、よく読まないで書いてある通りに操作するとMSIで入れてしまうという落とし穴もある。今のところVisual Studio 2017 で入るのは 2.1.0と大分古いバージョンだというのがいろいろな問題を面倒にしている。
問題点:MSI -> Install-Module でエラー
PowerShell Gallery と、MSI 経由のインストールには互換性が無く、MSI経由でAzure PowerShellが入った環境に PowerShell Gallery で新しいものを入れたりInstall-Module AzureRM、アップデートUpdate-Module AzureRmすることはできない。
例えば、Visual Studio 2017のインストールで、Azure PowerShellが入っている状態で、Install-Module AzureRMを やると下記のようなエラーになる。
$ install-module AzureRm
PackageManagement\Install-Package : The following commands are already available on this system:'Get-AzureStorageContainerAcl,Start-CopyAzureStorageBlob,Stop-CopyAzureStorageBlob'. This module 'Azure.Storage' may override the existing commands. If you still want to install this module 'Azure.Storage', use -AllowClobber parameter.
At C:\Program Files\WindowsPowerShell\Modules\PowerShellGet\1.0.0.1\PSModule.psm1:1809 char:21
+ ... $null = PackageManagement\Install-Package @PSBoundParameters
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidOperation: (Microsoft.Power....InstallPackage:InstallPackage) [Install-Package], Exception
+ FullyQualifiedErrorId : CommandAlreadyAvailable,Validate-ModuleCommandAlreadyAvailable,Microsoft.PowerShell.PackageManagement.Cmdlets.InstallPackage
つまり、MSIインストールとInstall-Moduleは互換性が無く、「混ぜるな危険」という状況だ。
解決策
もし混ざってしまったからどうするか。
MSIで入れたものを、設定画面の、「アプリと機能」、あるいはコントロールパネルの「プログラムのアンインストールまたは変更」からアンイストール後、再度 Install-Moduleで PowerShell Gallery からインストールする。
下記は、PowerShellからアンインストールする方法。実行には、Admin権限が必要。
$ $app = Get-WmiObject -Class Win32_Product -Filter "Name like '%Azure PowerShell%'"
$ $app
IdentifyingNumber : {CB3F8A12-1570-4964-8206-17274AB9EF4D}
Name : Microsoft Azure PowerShell - September 2016
Vendor : Microsoft Corporation
Version : 2.1.0
Caption : Microsoft Azure PowerShell - September 2016
$ $app.Uninstall()
これで下記のように入れ直すと入る。
$ Install-Module AzureRM
原因
MSIで入れた場合とInstall-Moduleで入れた場合、モジュールは別の場所に入る。
MSIの場合は、下記のPSModulePathに入り
C:Program Files (x86)Microsoft SDKsAzurePowerShellResourceManagerAzureResourceManagerC:Program Files (x86)Microsoft SDKsAzurePowerShellServiceManagementC:Program Files (x86)Microsoft SDKsAzurePowerShellStorage
Install-Moduleの場合は下記に入る
C:Program FilesWindowsPowerShellModules
MSIで入れた後にInstall-Moduleで入れた場合、MSIで入れたものを認識せずにインストールが進み、途中で別のバージョンのモジュールをロードして前記のエラーになる。Install-Moduleで入れた後に、MSIで入れると次のような問題が起きる。
MSIインストールの問題点
現在のMSIインストールで把握している問題点は3点ある(増えるかも)、そのうち深刻なのは1つ目の問題だ。
- Install-Moduleのモジュールを無条件上書きする
- Import-Module AzureRMでエラー
- WebPIでのリリースが遅い
1. Install-Moduleのモジュールを無条件上書
現在のMSIインストールは、Install-Moduleで入れたModuleがあれば削除してから、モジュールのインストールを行う。そのとき既存のモジュールのバージョンは見ていないので、Install-Moduleで4.0.1などのあたらしいバージョンを入れていても、VS 2017 を入れると、2.1.0になってしまうなどの現象が起きる。削除処理は、setup/Setup/RemoveGalleryModules.ps1のあたり。 Scope CurrentUserで入れた場合は考慮されておらず、なかなか残念なコードだ。
MSIだけで、バージョンアップを重ねている場合は、Windowsのインストールの仕組みでバージョンチャックされて古いバージョンは入らないので問題がないが、Install-Module(psget)で入れたものとの共存は考えられておらず、いきなり古いバージョンで上書きされるというわけだ。[3]
これは非常にメンドクサイ
2. Import-Module AzureRMでエラー
MSIで入れると、Import-Module AzureRmがエラーになる。これは、AzureRMというマニフェストモジュールが無いのが原因。Azure Poshの説明のあちこちで、Import-Module AzureRMが出て来るが、実はあまり意味がなく、モジュールはインストール時にModule Path配下に配置され、自動的にロードされるので、マニフェストモジュールが無くても動作上の不都合は無い。ただ、ドキュメントに書いてあるものがエラーになるのはちょと混乱する。ちなみに、Install-Module経由で入れてた場合は、AzureRM マニフェストモジュールが入り、Import-Module AzureRMも成功する。
$ import-module azurerm
import-module : The specified module 'azurerm' was not loaded because no valid module file was found in any module directory.
At line:1 char:1
+ import-module azurerm
+ ~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : ResourceUnavailable: (azurerm:String) [Import-Module], FileNotFoundException
+ FullyQualifiedErrorId : Modules_ModuleNotFound,Microsoft.PowerShell.Commands.ImportModuleCommand
3. WebPIでのリリースが遅い
なかなか、WebPIにリリースされない。今回だと、Managed Diskの機能がサポートされたバージョンはしばらく放置され、5/10にやっとリリースされた。最新版を使いたい場合は、Install-Module経由で入れるしかない。WebPIに頼らずに、GitHubからMSIをダウンロードして入れるという方法もある。[2]
まとめ
Azure PowerShell を使う場合、Install-Module AzureRMで入れる、VS 2017や以前WebPIで入れている場合は、一度コンパネからアンインストールしてから入れる。Windows 10より古い環境では、WMF 5.0を入れよう。
今のVS 2017は、リリースのたびにAzure PowerShellの古いバージョンを入れてくるが、挫けずにアンインストールしてから入れ直す。
現状だとGitHubからダウンロードして、MSIインストールで運用という手もあるが、推薦インストール方法がInstall-Module経由なので、そちらを取った方が無難だろう。VS 2017が原因で面倒なことになっているのは残念だ。
参考
| [1] | How to get PowerShellGetWMF 5.0 を入れようという話が書いてある |
| [2] | (1, 2) azure-powershell.4.0.1.msiリリースのとこに、msiへのリンクがある。 |
| [3] | VS Installer overwrite with old version Azure PowerShell.すぐTriaged になったけど、その後の動きがない。 |
Azure Cosmos DB がやってきた
DocumentDB の記事を書いていたら[15]、//Build 2017で、Azure Cosmos DB が発表[1]された。 Cosmos DBは、Multi-model database and multi-APIのGlobally Distributed データベース・サービスだ。

//Build 2017 Keynote より [1]
「DocumentDB何処行った、名前が変わったの?」と思ったら、そんなに簡単な話では無かった、Azure Cosmos DBは、DocumentDB、MongoDB, Azure Table,Gremlin などの複数のAPIをサポートしたマルチモデルの分散データベース[2]で Document DBはそのAPIの一つという位置づけになった。従来の Document DBで使ってた分散データベース基盤の部分は、ある程度汎用的に出来ていてJSON以外のデータモデルも扱えるので、今回はKey-Value と GraphのデータモデルにAPIを付けてブランディングも新たにお披露目したよという話だ。素晴らしい。
ざっくりまとめると、下図のような感じになってる。Cosmos 分散データベース基盤に、データモデルが乗っていて、それぞれAPIを提供するといった感じだ。AzureTable(Key-Value), Gremlin(Graph) は、Preview(既に試すことができる)で、Splark は、アナウンスだけ、DocumentDBとMongoDB APIはGAのままだ。この2つがGAのままなのは、Cosmos DBになっても基本的な実装は同じだからだろう。

Azure Cosmos DB スタック
Breakout Session
//Build 2017のCosmos DBの2つのBreakout Session、B8047[3]と、T6058[4]では、もう少し詳細に触れられている。
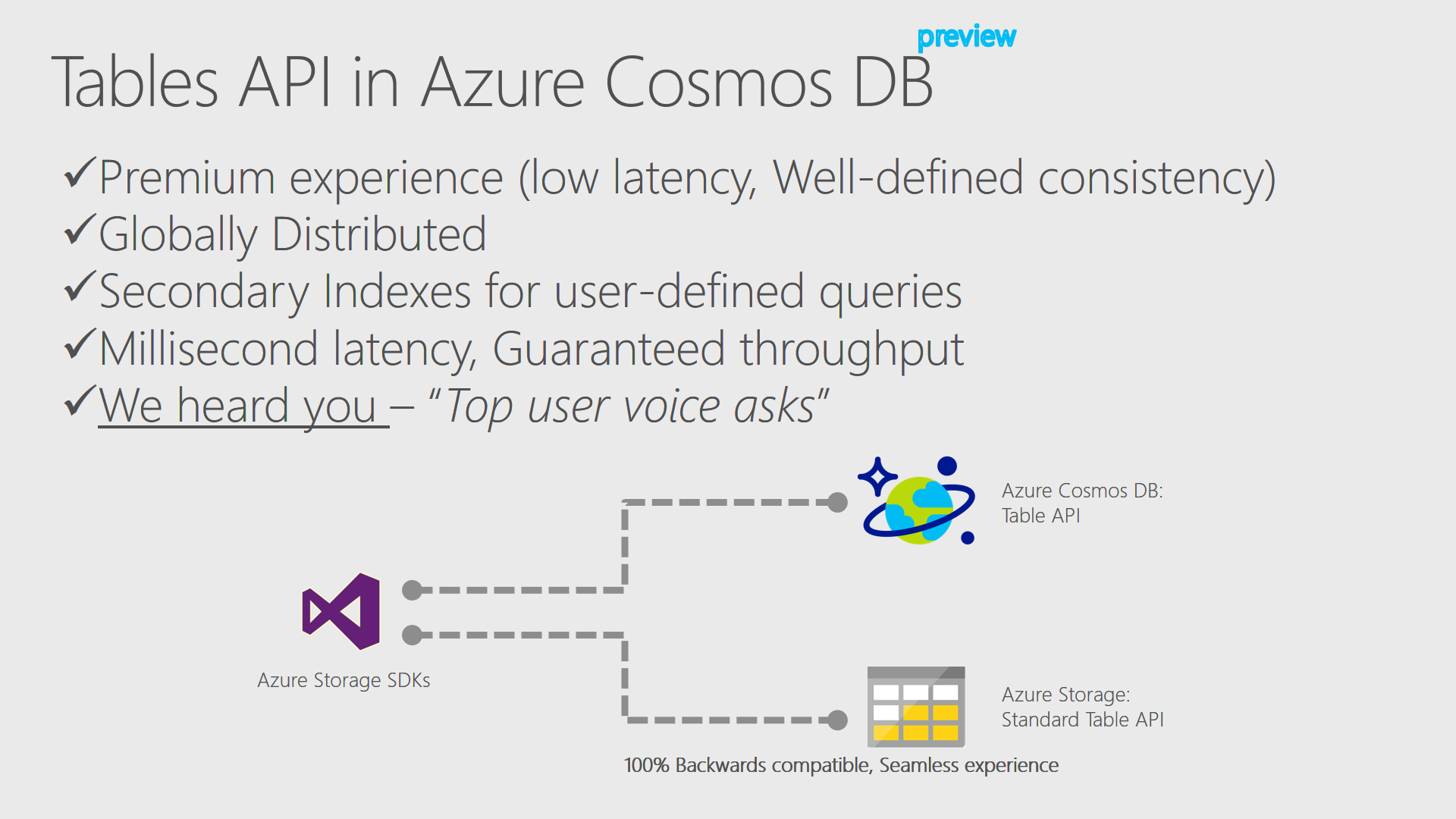
//Build 2017 B8047 より [3]
その中でも興味深いのは、B8047 のTable APIの下りだ(動画だと35:50あたり[5])。超訳すると。
Cosmos DB に、既存のTable Storage(以下Standard Storage)互換のTable API(以下Premium Table)を実装した。もう、Premium Table SDK[6]をダウンロードして試せる。アプリケーションの変更は必要ない(SDKでを切り替えるだけ)で、ローレイテンシー、5つの一貫性、グローバルディストリビューション、セカンダリーインデックス等、数々のCosmos DBの特性が得られる。
特に重要なのは、これに続く部分だ。
現在「storage optimized offer」に向けて作業中、現在の Cosmos DB は、スループットの最適化、ローレイテンシーなどのpremium experience にフォーカスしているが、hot work load 以外の場合でも選択肢にできるように取り組んでいる。
現在のCosmos DB(旧DocumentDB)の料金体系は、基本hot work load向けだ。アクセス頻度が低いデータが多くなってくるとAzure Storageとのコスト差がどんどん大きくなっていく。データ全体の中で一部だけのアクセス頻度が高く、殆どのデータはアクセス頻度が低い場合は、Cosmos DBだけでなく、なんからの外部データストアとの連繫を検討する必要がある。これは特に、Standard Table(これからは、Azure Table StorageのことはStandard Tableと呼ぼう)からの移行を考えた時に重要な検討課題だろう。それがうまく解決できるなら、かなり有り難い。
同時に公開されたBlogから
Cosmos DBも発表共に公開されたBlogもなかなか面白い。Azure Cosmos DB: The industry’s first globally-distributed, multi-model database service[7]の A Brief History of Cosmosには簡単なCosmos DBの歴史が書いてあった。それによると、
Azure Cosmos DBは、2010年に「Project Florence」で開始、グローバルディストリビューションの課題を解決するためにMSの社内で使っていたが、他の皆にも役に立つと思い、2015年にAzure DocumentDBの形でこのテクノロジの第1世代を利用できるようにした。
云々だそうだ。世界中で展開するサービスの下りをみて連想したのは、AzurePortal。「最近ポータルが速くなってきてるのはエンドポイントを日本に持ってきたからかな、でもUSのリソースも普通に見れて操作できるしどうなっているのだろう」と思っていたが。Cosmos DBのようなグローバルディストリビューションの仕組みがあれば実装イメージが湧いてくる。実際のところはどうなっているかはわからないが。なかなか興味深い。
あとA technical overview of Azure Cosmos DB[8]に、Leslie Lamport 博士が出てきて、Cosmos DBの一貫性の設計、実装にTLA+[9]のCosmosでの活用の話をしていたのが興味深かった。[9]
「正しく動く分散システムを作るのはなかなか難しい、そんな中で形式手法が有効だ。Cosmos DBは設計、実装で、TLA+が複数の一貫性のサポートやSLAの提供に貢献した」的なことを言っている(超訳過ぎるので原文参照)。AWSでは、2011年からFormal Methodsを使って、重要な分散システムのアルゴリズム設計を行っている[10]と話題になったが、MSが分散システムの設計に使っている公言したのは初めてな気がする。利用者サイドからの一貫性の検証は難しいので設計、実装の取り組みがわかるのは有り難い。
この記事には、Azure Cosmos DBのデータベースエンジンの中身についても少し書いてあった。以下超訳
Azure Cosmos DBのデータベースエンジンのコアタイプシステムは、汎用的にどのようなデータにも対応するatom-record-sequence (ARS)と呼ばれる構造となっている。Atomは、文字列、論理型、数値などのprimitive型、recordは構造体、sequence はatom、record、sequenceの配列である。また、Azure Cosmos DBのデータベースエンジンは、JSONなどのAPIが利用するデータモデルとARSベースのコアデータモデルの効率的な変換と投影を実装し、動的型付き言語(dynamically typed programming languages)からコアデータモデルへのネイティブアクセスをサポートする。このデータベースエンジンを使うことで、Cosmos DBのAPIは、battle-tested でフルマネージドな、グローバル分散型データベースシステムのすべての利点を得ることができる。
ARSは、プリミティブ型を単純に並べただけの構造なのでJSONをそのまま保存するよりは効率は良いだろうし、別のデータモデルを実装し易いだろう。コアデータ・モデルを扱うデータベースとしての基本的な部分、整合性、リプリケーション、バックアップなどは共通の仕組みが使えるというわけだ。
まとめ
つらつらと書いていたら随分長くなってしまった。これで、Graph APIの話とかTLA+の話も書きたかったが疲れたので、この辺で一旦終わる。最初、Premium Tableを聞いた時は、DocumentDB時代の価格体系だとちょと用途が限定される気がして、どうなのかとも思ったが、B8047[5]の話を聞いて、今はとても期待している。
今の気分は、「Cosmos DBはいいぞ」と言う感じだ。
追記 (2017/5/15)
現在のTable APIではパーテーション無しコレクションしか作成できず、コレクションの容量は10GBだ。これはプレビューの制限だと思われる。10GB以上のデータで評価したい場合は要注意だ。現時点でもスループットは、10万 RU/秒まで設定でき、Standardのストレージアカウント全体のパフォーマンスターゲット(1Kエンティティで毎秒20,000トランザクション)[14]を上回る。また、Table StorageのTableがCosmos DBのコレクションになるので、Table単位で課金される。Standardだと割りと気軽にTableを作れたのでこれも設計変更の要因になるだろう。
脚注
| [1] | (1, 2) [1:22:26]Azure Cosmos DB Introduction |
| [2] | [1:27:20]Rimma Nehme, Azure Cosmos DB demonstration |
| [3] | (1, 2) B8047 How to build globally-distributed, fast, billion-user applications with Azure Cosmos DB |
| [4] | T6058 Azure Cosmos DB: NoSQL capabilities everyone should know about |
| [5] | (1, 2) [0:35:50]B8047 のTable APIの部分 |
| [6] | Premium Table SDKソースは未公開 |
| [7] | Azure Cosmos DB: The industry’s first globally-distributed, multi-model database service |
| [8] | A technical overview of Azure Cosmos DB |
| [9] | (1, 2) Foundations of Azure Cosmos DB with Dr. Leslie Lamport, longレスリー ランポート先生のインタビュー、お勧めです。 |
| [10] | How Amazon Web Services Uses Formal Methods |
| [11] | Getting started with Azure Cosmos DB: Table API |
| [12] | 接続文字列の切替部分 |
| [13] | AppSettingsでの設定箇所 |
| [14] | Blob、キュー、テーブル、およびファイルのスケーラビリティ ターゲットサンプルコードでは、IDでの読込が1 RU/秒程度、エンティティ作成が10 RU/秒程度を消費していた。それをベースに試算すると、読込はStandard Tableのストレージアカウントの10倍、書込は同等のスループットということになる。ここでは、Read/Write混合を想定して「上回る」という表現にした。 |
| [15] | 日経クラウドファースト 2016年6月号Azure DocumentDB 予約性能と実測値がほぼ一致 応答時間はデータストアーで最高レベル |