Windows Azure Storage 2.0 の Blob Upload
前の記事Azure Storage Gen 2は速かったでは非同期呼び出しを使っていますが、これには理由があります。以前(2010年ぐらい)、Windows Azureを使い始めたころにSorage Client 1.xと、.NET Framework 4.0の組み合わせでいろいろ試した時には、スレッドを上げてやったのと非同期にしてやったので比べた時には有意な違いは出ませんでした。非同期でコードを書くと面倒になることも多かったので、「手間の割にはあまりメリットは無いなあ」というのが当時の結論だったのです。
ところが、2012年10月の末にAzure Storage Client 2.0が出てAPIや実装が大幅に変わったので変更点を眺めていたら面白いことに気が付きました。2.0ではBlobの書き込みは、Stream.WriteToSync()でやっていて、そのWriteToSyncの中が非同期呼び出しで実装されているとか、非同期呼び出し数をセマフォを使って制限しているところなどなかなか良さげな実装になっています。
ある日、AzureLargeFileUploaderというのがGitHubに上がっているのに気が付いて中を見てみたら、前に読んだSDKの実装に比べても、そんなに優れているようには見えません。「あのコードより2.0の実装の方が大きなファイルでも効率的にUploadできるはず、もしかしたら2.0のコードは壊れているのからこんなことしてるのかな?」と思い2.0のコードを動かして実際に試して見ました。やってみたらなかなか調子が良く2.0の実装では十分な速度でBlobにアップロードされます。
C# 5.0で await/asyc もサポートされ .NET 4.5になってTask周りも改善されて非同期を使うには良い環境が揃ってきていると感じました。それで改めて非同期呼び出しを使ってみることにしました。

試行(やってみた)
Azure Datacenter内にLargeのインスタンスを用意して適当なファイルを元にして8GBのファイルを用意しました。そのファイルを同一のBlobに4回アップロードして平均の速度を測定します。結果は、 ** 平均473Mbps ** でした。これは、ほぼインスタンスのネットワーク帯域制限値と同じです。なかなか良い結果と言えます。
確認に使ったコード、(メッセージがドイツ語になっているのは、AzureLargeFileUploader の名残です)
このコードのポイントは下記の3点です。
- 18行目ので接続数の制限を1024に設定していること
- 59行目で並列度の設定をコア数の12倍にしていること
- 55,56行目ではPage/Block Blobのどちらを使うかを切り替えていること
接続が作れないと並列度が上がらないのでDefaultConnectionLimitを増やし、Storage Client 2.0ではParallelOperationThreadCount のデフォルトが1になっているのでコア数の12倍に設定します。Storage Client 2.0では、55, 56行目のように切り替えるだけで、どちらでも並列アップロードができるようになっています。1.xのときは、UploadFromStreamを使った時にBlock Blobでしか並列アップロードがサポートされてなかったことに比べて改善されています。
アップロード中をリソースマネージャーで観察するとコネクションが数多く作成されているのが確認できます。右側のNetworkトラフィックのグラフが波打っているのが興味深いところです。ピーク時に600-700Mbps程度行くこともありますが平均すると470 Mbpsという結果でした。CPUは5-10%程度しか使われていませんし、メモリーも開始から終了までほぼ一定です。なかなか優秀です。
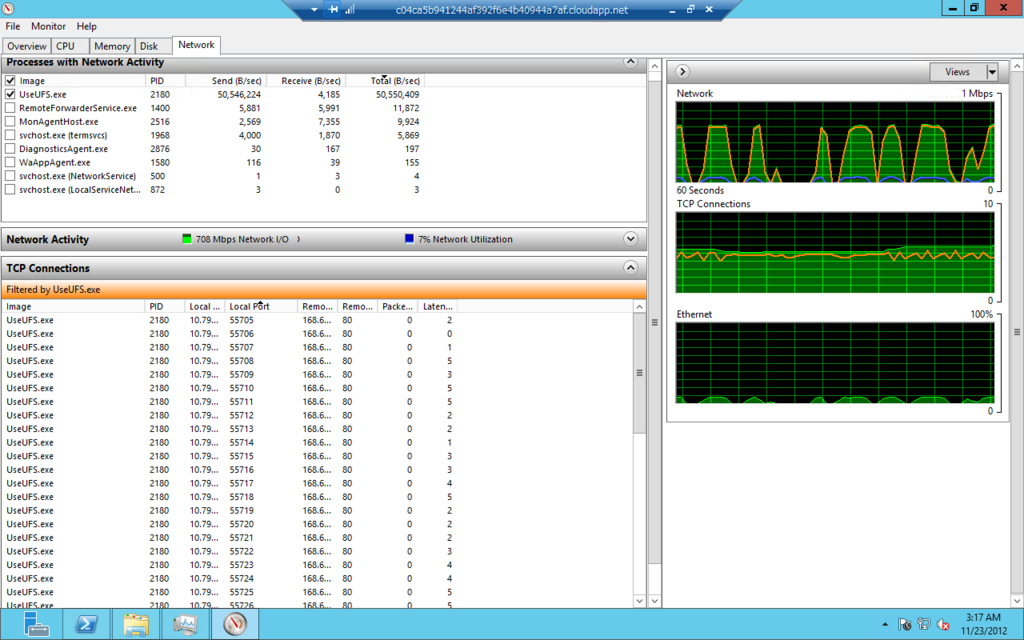

** ここからは、ソースを見ながら確認していった過程のメモです。リンクばかりで分かり辛いかもしれませんが参考までに。興味深いのは非同期と同期の処理の境界と並列度の制限をしている部分です。 **
どうしてこんなところが変わったの? ParallelOperationThreadCount のデフォルト値
1.x では
CloudBlobClientに、ParallelOperationThreadCount というのがあります。1系では、下記のように定義されていました。
StorageClient/CloudBlobClient.cs#L261
試しに、下記のようなコードでioThreadsを確認したところデスクトップPCでは2,Azure上のLargeのインスタンスでは4でした。どちらの環境でもデフォルトでParallelOperationThreadCountが2以上になり並列で動作します。
2.0 では
それに対し、2系では下記のように定義されています。parallelismFactorは、47行目付近で1で初期化されておりデフォルトは1となります。
これからParallelOperationThreadCount のデフォルトが1に変わったことがわかります。これは、Windows Azure Storage Client Library 2.0 Breaking Changes & Migration Guideにも書いてあるBreaking Changesです。
2.0に移行した後、Block Blobのアップロードが遅くなった場合はParallelOperationThreadCountを確認するといいかもしれません。
ParallelOperationThreadCountの使われ方
1.xでは、ParallelOperationThreadCount は、ParallelUpload で並列度の定義になっています。このクラスは、Streamをblock blobにUploadするもので、BlobClient.UploadFromStreamを、Block blobで使った時しか使われません。** Page Blobでは並列アップロードは実装されていません。 ** おそらく、SDK 1xではPage Blogのパラレルアップロードをサポートしていないので、AzureLargeFileUploaderを用意したのだと思います ** あのソースだけだと分からないですが
ParallelExecute あたりの処理をみると、Block毎にTaskを上げているらしいことがわかります。ParallelUpload.cs#L148
2.0.1では、CloudBlockBlob のUploadFromStreamは、並列処理をするときにはStreamの拡張メソッドのWriteToSyncを呼んでいます。CloudBlockBlob.cs#L116
同期と非同期の境界
WriteToSyncの実装は下記のようになっています。StreamExtensions.cs#L64
ちょっと見ると、WriteToSyncは、読み込み側のStreamを非同期で読み出すためのフラグをもっているだけで書き込みは同期していて、並列動作しないような感じです。これだと、ParallelOperationThreadCountに2以上をセットしてもパラレルアップロードは行われないのかな?と思いますが、その先のtoStream.Write の実装を見ると内部が非同期に処理されています。
toStreamの実態は、BlobをStreamとして扱うBlobWriteStreamのインスタンスで、これは内部的に非同期で書き込みを行います。
呼び出し側を見ると同期処理のように見えるが、BlobWriteStreamBase で、AsyncSemaphore parallelOperationSemaphoerをParallelOperationThreadCountの数で初期化しており、ストーリーム内のブロック書き込みは非同期に行われています。
この設計はなかなかイイ。
非同期実行数の制限
ここで、AsyncSemaphoreは、既定の数以上に処理が実行されないように非同期実行数を制御している役割を果たしている。
BlobWriteStreamでは、書き込みが全部終わると、最後に PutBlockList して終了する。同様な処理がPage Blobにも用意されていて並列アップロードされるような実装になっている。
このあたりは、What’s New in Storage Client Library for .NET (version 2.0)に書いてある説明通りの実装になってるようだ。
結論
Blobのアップロードのような I/O がボトルネックとなるような処理ではI/O の非同期を使うことでCPU、メモリの負荷を最低限にして効率的に処理をすることができる。このコードでは、Stream 書き込みの内部処理を非同期化することで全体のパフォーマンスを向上しプログラミングモデルへの影響は最低限にしている。サーバーサイドのプログラミングではこのような、同期、非同期の境界を発見して設計することが重要だと言える。非同期実行数の制限もなかなか興味深い。
おまけ
LargeのRoleからStorageにUploadしたら450Mbps程度の速度が出た。ローカルからも、20Mbps程度だったので結構速い。転送中を見ていると、しばらくは複数のコネクションを使ってデータ転送していて最後にコネクションが一本になって終わる。、
PutBlobを非同期でやって最後にPutBlobListで終了となってるようだ。PutBlobの処理中はCPUはほとんど使われずに、ネットワーク帯域がボトルネックになっるぐらいには効率がいい。最後のPutBlobListの間はStorage側の待ちになってしまう。
これを考えると、複数のファイルをUploadする場合は、スレッドを分けて個々に処理した方が短時間で終わるのではないかと考えられる。ただ、あまり多くのスレッドを起動するメリットは無さそうだ。
今回は、UploadFromStreamを使ったが下記の説明にはOpenWriteを使うとStreamのように処理できると書いてある。やってみたら同じように動いた。つまりBlobをStreamとして使えるってことだ素晴らしい。
Azure Storage Gen 2は速かった
今年も早いもので、あっという間に12月になりました。個人的なAzure今年の目玉は、Azure Storageのパフォーマンスの向上(Gen2)と新しくなったWindows Azure Storage 2.0です。
IaaS、Web Site、Mobile Service、Media Serviceなど新機能満載なAzureですが、目立たないところで地味にストレージ関連は改善されています。ストレージはクラウドの足回りなので重要です。
- 元記事は、Windows Azure Advent Calendar 2012 2日目として書きました。Windows Azure Advent Calendar jp: 2012

Azure Storageのパフォーマンスの向上
2012/6/7 以降に作成されたストレージアカウントで、下記のようにパフォーマンスターゲットが引き上げられました。Gen 2と呼ばれているようです。以前のもの(Gen1)に比べ秒間のトランザクションベースだと4倍程度になっています(Azure Table 1Kエンティティの場合)
詳しくはリンク先を見てもらうとして下記の4点が注目です。
- ストレージ ノード 間のネットワーク速度が1Gbpsから10Gbpsに向上
- ジャーナリングに使われるストレージデバイスがHDDからSSDに改善
- 単一パーテーション 500 エンティティ/秒 -> 2,000 エンティティ/秒 (15Mbps)
- 複数パーテーション 5,000 エンティティ/秒 -> 20,000 エンティティ/秒 (156Mbps)
確認しよう
ではどれだけ速くなったのか確認しましょう。なるべく実利用環境に近いようにということでC#を使います。ライブライは、最近出たばかりですが、Azure Storage Client 2.0を使います。このライブラリのコードをざっと見た感じだと、従来のコードに比べてシンプルになって読みやすく速度も期待できそうです。
比較的限界が低い単一パーテーションで確認します。前記のGen2の記事には、エンティティが1KByteで、単一パーテーションの場合、2,000 エンティティ/秒というパフォーマンスターゲットが記述されています。これを確認しようとするとAzure外部からのネットワークアクセスだと厳しいのでWorkerRoleを立てて、リモートデスクトップでログインしてプログラムを実行します。プログラムは秒間2000オブジェクトを計測時間の間は作りづけないといけないのでCPUやGCがボトルネックになるかもしれません、今回はLargeのインスタンスを使うことにしました。
Largeだとメモリ7GByte、coreが8つ、ネットワーク400Mbpsというスペックなので気にしなくても良いかと思ったのですが、GCをなるべく減らすためにエンティティのデータ部分をCache(共有)します。1KByteぐらいだとあまり効果が無いかもしれませんが。
さらに、Threadを上げる数を減らして並列性を上げるために非同期呼び出しを使います。.NET 4.5 から await/async が使えるので割合簡単に非同期コードが記述できるのですが、少し手間がかかりました。
なんと残念ながら、Windows Azure Storage 2.0になっても APM (Asynchronous Programming Model) のメソッドしか用意されておらず、 await で使えるTaskAsyncの形式がサポートされていません。仕方がないので、自分で拡張メソッドを書きますが、引数が多くて intellisense があっても混乱します。泣く泣く、コンパイルエラーで期待されているシグニチャーをみながら書きました。コードとしてはこんな感じで簡単です。
この辺りは、下記のサイトが詳しくお勧めです。
非同期で同時接続数が上がらない?
このコードを動かしてみたら、「単一スレッド+非同期の組み合わせだと、おおよそ2から3程度のコネクションしか作成されない」ことに気が付きました。場合によっては、5ぐらいまで上がることもあるようですが、どうしてこうなるのか不思議です。
#### ** これは、Azure Storage Client 2.0のBUG ** だったようです。2.0.2で修正されています。WindowsAzure/azure-sdk-for-net Issue #141
** [2012/12/26 このFIXに関するまとめを書きました](Azure Storage Client 2.0 CompletedSynchronously FIX) **
非同期でガンガンリクエストが飛ぶのかと思ったのですが、それほどでもなかったので、今回のコードは複数スレッド(Task)をあげて、それぞれのスレッド内で非同期呼び出しを使って処理を行うようになっています。Taskの起動には、Parallel.ForEach を使っています。
さらに、上限に挑戦するためにEntity Group Transactionを使います。TableBatchOperation のインスタンスを作って操作を追加していってCloudTableのExecuteBatchAsync()で実行します。この辺りは以前の使い方とだいぶ違っています。今回は時間を測っているだけですが、resultにはEntityのリストが帰ってきて、それぞれにtimestampとetagがセットされています。
—
結果
いくつかパラメータを調整して実行し、スロットリングが起きる前後を探して4回測定しました。ピークe/sは、もっとも時間当たりのエンティティの挿入数が大きかった時の数字で秒間のエンティティ挿入数を表しています。単一プロセスでスレッドを増やしていく方法では頭打ちになってしまうので、複数のプロセスを起動して測定ています。(このあたりも少しオカシイです)下記の表の最初のカラムは起動するプロセス数です。
失敗が無かったケースで6,684、 6,932 エンティティ/秒で処理できており、Gen2で挙げられているパフォーマンスターゲットは十分達成できているようです。
測定時間の、Table Metricsを見るとThrottlingErrorと同時に、ClientTimeoutErrorも出ているのでプロセスを3つ上げているケースではクライアント側でサーバからの戻りが受けきれずにエラーになっている場合も含まれているようです。
| プロセス数 | 最少 | 中央値 | 平均 | 最大 | 90%点 | 95%点 | 99%点 | ピークe/s | 成功数 | 失敗数 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 97.27 | 166.6 | 258 | 14,800 | 359.578 | 472.373 | 1,106.28 | 6,684 | 40,000 | 0 |
| 2 | 94.17 | 260.5 | 333.7 | 5,320 | 564.774 | 723.272 | 1,339.03 | 6,932 | 40,000 | 0 |
| 3 | 90.13 | 174.8 | 734.1 | 21,270 | 1,621.49 | 1,845.90 | 3,434.26 | 7,218 | 59,377 | 623 |
| 3 | 90.35 | 341.6 | 610.1 | 27,490 | 1,064.59 | 1,380.42 | 4,431.79 | 8,005 | 59,740 | 260 |
最後に
今回、第一世代(Gen 1)の単一パーテーションで500 エンティティ/秒というパフォーマンスターゲットに比べ10倍近いパフォーマンスを出しているのが測定できました。測定時間が短かったので、継続してこのパフォーマンスがでるのかどうかなど検証の余地はありますが、劇的に向上していると言えます。takekazuomi/WAAC201202のレポジトリに計測に使ったコードをいれてあります。
12/2の担当でしたが、JSTでは日付も変わってだいぶ遅くなってしました。データの解析に最近お気に入りの(慣れない)「R」を使ったのですが、いろいろ手間取ってしまいました。最初はRで出した図なども入れたいと思ったのですが、軸や凡例の設定がうまくできずに時間切れで断念です。
レポジトリには、なんかずいぶん古い履歴まで上がってしましたが、手元のコードを使いまわしたら出てしまいました。スルーでお願いします。
おまけ
数時間振り回してみると、エンティティ/秒の中央値は2000から3000エンティティ/秒程度になりそうです。負荷がかかり始めると、Gen 1ではスロットリングをかけてエラーにしてしまうという動きでしたが、Gen 2 ではスロットリングを随時掛けつつ2000から3000エンティティ/秒程度に絞っていくという動きになったようです。`